
success story

Architettura OSINT fragile che brucia il 94% del budget infrastrutturale

Tipo
Legacy Rescue & Modernization
Anno
2022 - Ongoing
success story
Legacy Rescue & Modernization
2022 - Ongoing
Un Cliente internazionale che crea servizi e tecnologie in ambito Finance ci ha contattato per valutare le criticità di un prodotto SaaS OSINT ereditato da una acquisizione precedente. Il sistema era cresciuto in modo disordinato: costi infrastrutturali elevati, bassa affidabilità, difficoltà di manutenzione e un time-to-market sempre peggiore
Con il Cliente avevamo già collaborato con successo in passato; questo ha accelerato l’avvio del lavoro e ha consentito un percorso incrementale: stabilizzazione dell’esistente, riprogettazione graduale, e una fase evolutiva/di mantenimento tuttora attiva
L’ingaggio ha previsto una prima fase di assessment, la nostra Technical Due Diligence, una seconda fase di ri-progettazione incrementale e una terza fase evolutiva e di mantenimento, tuttora in corso.
La richiesta era chiara: rimettere in carreggiata una piattaforma nata con un’ottima intuizione di servizio ma divenuta, nel tempo, un sistema fragile e costoso da gestire.
Al momento dell’ingaggio la piattaforma conteneva circa 50 miliardi di record, per un totale di 12,5 TB. Tuttavia, il sistema si presentava poco affidabile, oneroso da mantenere e sempre più difficile da evolvere.
L’infrastruttura era cresciuta in modo disordinato, con un impatto diretto su costi, manutenzione e scalabilità.
In questo scenario, la nostra attività di Technical Due Diligence è stata determinante. Abbiamo analizzato infrastruttura, codebase, configurazioni e flussi dati end-to-end (ingestion → normalizzazione → indicizzazione → ricerca → watchlist). La mappa delle criticità emersa includeva:
architettura eccessivamente complessa e ridondante, con frammentazione della logica su numerosi componenti e moduli, e un alto numero di failure mode operativi;
scelte tecnologiche non coerenti con gli obiettivi NFR (Non Functional Requirements), spesso dettate dalla popolarità degli strumenti piuttosto che dalla loro adeguatezza funzionale – tra cui l’impiego di ElasticSearch come database primario per flussi che richiedevano coerenza immediata;
assenza di meccanismi di deduplicazione e protezione contro abusi (rate limiting), con impatto negativo su performance e sostenibilità;
ecosistema tecnologico frammentato, incluse dipendenze improprie da stati temporanei (es. coordinamento e metadati transitori gestiti in modo fragile), supervisione incompleta dei processi e osservabilità non omogenea
costi infrastrutturali sproporzionati rispetto al valore generato.
In parallelo, abbiamo formalizzato i vincoli del dominio: dataset dell’ordine di decine/centinaia di miliardi di documenti con crescita mensile importante; query real-time di tipo exact-match su un singolo campo; necessità di creare nuovi indici con impatto minimo sul servizio; carichi di ricerca “spiky”; e un sistema di watchlist che salva e notifica nuovi match.
Interventi rapidi e mirati, per garantire la continuità operativa e ridurre l’attrito nelle attività quotidiane;
Roadmap di medio-lungo periodo, per e sostituire gradualmente i componenti critici con soluzioni più semplici, robuste ed economiche, riducendo complessità e costi;
Spike tecnici e proof-of-concept, discussi regolarmente con il Cliente per validare le assunzioni (tempi di query, tempi di reindex, costi di update e query) e guidare decisioni architetturali con dati misurabili.
In un contesto complesso come quello ereditato, il nostro obiettivo era duplice: semplificare radicalmente l’architettura garantendo prestazioni, affidabilità e scalabilità. Abbiamo quindi adottato un approccio “mechanical sympathy”: ridurre i componenti e le dipendenze, sfruttare primitive cloud gestite e costruire percorsi dati lineari, misurabili e facilmente ottimizzabili
Abbiamo realizzato un motore di indicizzazione e ricerca basato su un principio semplice: suddividere il dataset in partizioni deterministiche su AWS S3 in modo da rendere ogni interrogazione un accesso mirato a una porzione piccola e prevedibile dei dati.
I dati indicizzati vengono organizzati in partizioni autonome su object storage, costruite con una logica hash-based (hash-prefix).
In fase di query, il sistema calcola la chiave di partizionamento e recupera solo la partizione pertinente, completando la selezione con un filtro in memoria per l’exact-match.
La struttura consente di creare o rigenerare indici in modo indipendente, riducendo l’impatto sul servizio e semplificando le attività di reindex.
Questa scelta abilita lookup time stabile, scalabilità naturale tramite compute on-demand e un controllo più rigoroso dei costi rispetto ad approcci basati su componenti always-on.
Abbiamo ristrutturato i flussi di ingestion rendendoli lineari e osservabili, standardizzando formati e regole di trasformazione lungo tutto il percorso (ingestion → normalizzazione → master → indicizzazione).
Definizione di schemi coerenti e versionabili per ridurre ambiguità e regressioni.
Utilizzo di algoritmi di compressione mirati al miglioramento dell’ efficienza di storage e throughput, mantenendo buone prestazioni in lettura.
Supporto nativo a reindex completi e aggiornamenti incrementali, per evitare riscritture massive e ridurre tempi/costi dei cicli di aggiornamento.
Dove possibile abbiamo spostato il carico operativo verso servizi AWS gestiti, riducendo la complessità sistemica e i punti di failure.
AWS S3 come storage durevole e scalabile per master copy e indici.
Compute on-demand per query e funzioni di ricerca, particolarmente efficace su carichi bursty.
Code gestite e job containerizzati per disaccoppiare ingestion e indicizzazione, introducendo backpressure controllabile e parallelizzazione.
Abbiamo introdotto un livello di governance per rendere la piattaforma più robusta e sostenibile nel tempo:
Controllo degli accessi e throttling per endpoint/tenant, limitando utilizzi impropri e stabilizzando la latenza.
Accounting e tracciamento delle operazioni principali per supportare rendicontazione, cost allocation e capacity planning.
Infine, abbiamo reso l’intero sistema più “operabile” in modo strutturale:
logging strutturato e metriche sui passaggi chiave (ingestion lag, tempi di indicizzazione, error rate, latenza query).
identificazione e rimozione dei colli di bottiglia più impattanti, con un ciclo continuo di misurazione e ottimizzazione.
L’intervento ha prodotto risultati misurabili sia sul piano tecnico sia sul piano economico:
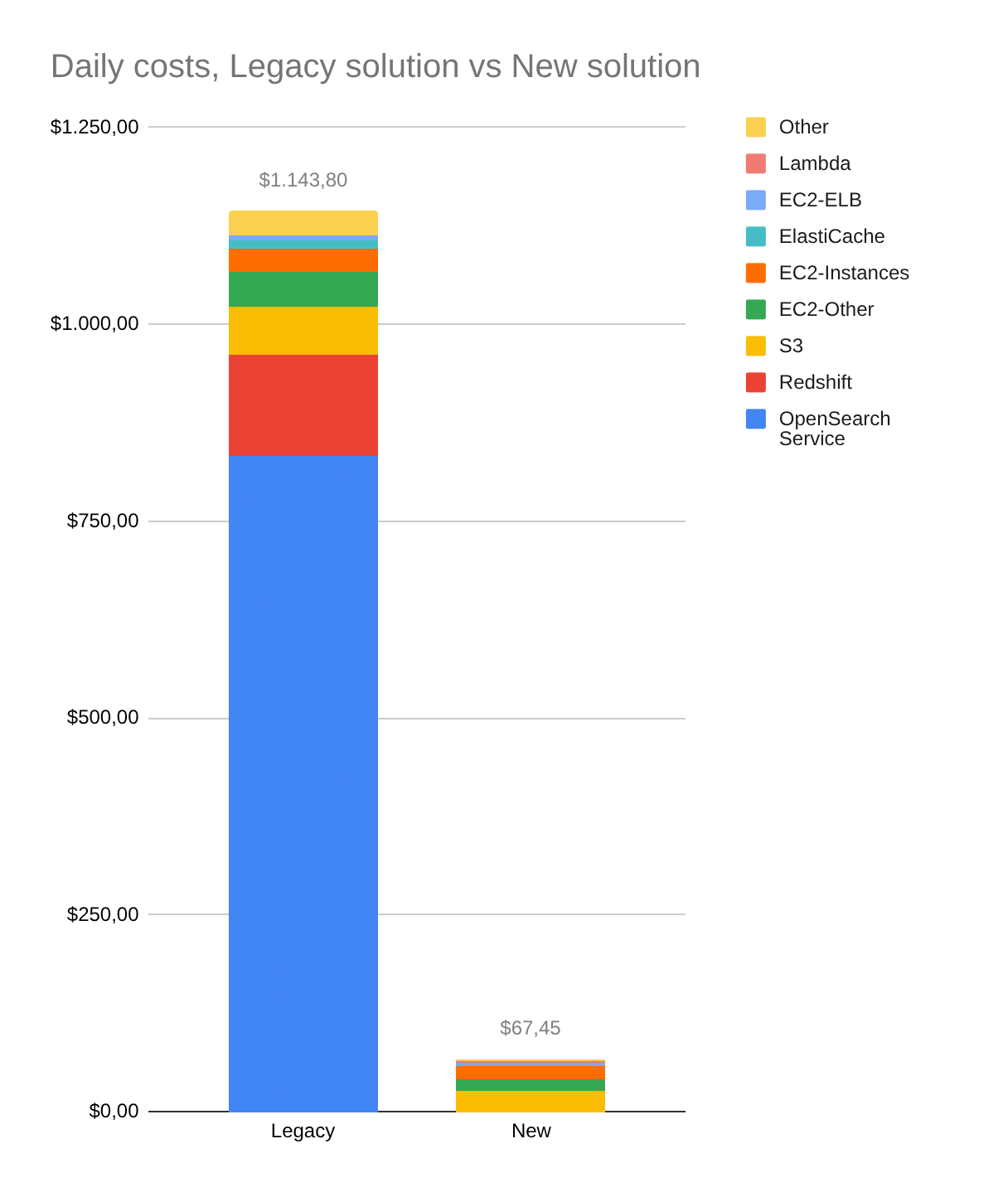
Riduzione dei costi infrastrutturali AWS di circa il 94%, con costi mensili scesi da ~34.000$ a ~2.000$ a parità di volumi (circa 17× in meno);
Scalabilità dimostrata, la pipeline di ingestion ha sostenuto un aumento continuo dei volumi, passando in un anno da ~50 miliardi di record (12,5 TB) a ~250 miliardi di record (62 TB);
Time-to-market migliorato, un’architettura più semplice da estendere ha permesso integrazioni più rapide con servizi terzi e nuove funzionalità, riducendo il rischio di regressioni e la complessità di rilascio;
Operabilità superiore, meno punti di failure, più osservabilità e diagnosi più rapide.
-93%
costi operativi
+400%
volume dei dati gestiti
1 anno
(con fase evolutiva e di mantenimento attiva)Grazie alla nuova architettura, oggi il Cliente può contare su una piattaforma OSINT SaaS snella, sostenibile e di nuovo in crescita: una base tecnica solida, progettata per scalare su dataset massivi e mantenere sotto controllo la spesa cloud.
Al di là degli aspetti tecnici, il progetto ha potuto dare i risultati descritti grazie al rapporto di fiducia reciproca e a un metodo di lavoro pragmatico: assessment rigoroso, scelte validate con POC, migrazione incrementale e allineamento costante ai vincoli di business (costi, manutenibilità, evolvibilità).